Comparing the performance of OpenCL, CUDA, and HIP
The Futhark compiler supports three GPU backends that are equivalent in functionality and (in principle) also in performance. In this post I will investigate to which extent this is true. The results here are based on work I will be presenting at FPROPER ’24 in September.
Background
In contrast to CPUs, GPUs are typically not programmed by directly generating and loading machine code. Instead, the programmer must use fairly complicated software APIs to compile the GPU code and communicate with the GPU hardware. Various GPU APIs mostly targeting graphics programming exist, including OpenGL, DirectX, and Vulkan. While these APIs do have some support for general-purpose computing (GPGPU), it is somewhat awkward and limited. Instead, GPGPU applications may use compute-oriented APIs such as CUDA, OpenCL, and HIP.
CUDA was released by NVIDIA in 2007 as a proprietary API and library
for NVIDIA GPUs. It has since become the most popular API for GPGPU,
largely aided by the single-source CUDA C++ programming model provided
by the nvcc compiler. In response, OpenCL was published in 2009 by
Khronos as an open standard for heterogeneous computing. In
particular, OpenCL was adopted by AMD and Intel as the main way to
perform GPGPU on their GPUs, and is also supported by NVIDIA. For
reasons that are outside the scope of this post, OpenCL has so far
failed to reach the popularity of CUDA. (OK, let’s expand the scope a
little bit: it is because OpenCL has terrible ergonomics. Using it
directly is about as comfortable as hugging a cactus. I can’t put
subjective opinions like that in my paper, but I sure can put it in a
blog post. OpenCL is an API only a compiler can love.)
The dominance of CUDA posed a market problem for AMD, since software
written in CUDA can only be executed on an NVIDIA GPU. Since 2016, AMD
has been developing HIP, an API that is largely identical to CUDA, and
which includes tools for automatically translating CUDA programs to
HIP hipify. Since HIP is so similar to CUDA, an implementation of
the HIP API in terms of CUDA is straightforward, and is also supplied
by AMD. The consequence is that a HIP application can also be run on
both AMD and NVIDIA hardware, often without any performance overhead,
although I’m not going to delve into that topic.
While HIP is clearly intended as a strategic response to the large amount of existing CUDA software, HIP can also be used by newly written code. The potential advantage is that HIP (and CUDA) exposes more GPU features than OpenCL, as OpenCL is a more slow-moving and hardware-agnostic specification developed by a committee, which cannot be extended unilaterally by GPU manufacturers.
The compiler
The Futhark compiler supports three GPU backends: OpenCL, HIP, and CUDA. All three backends use exactly the same compilation pipeline, including all optimisations, except for the final code generation stage. The result of compilation is conceptually two parts: a GPU program that contains definitions of GPU functions (kernels) that will ultimately run on the GPU and a host program, in C, that runs on the CPU and contains invocations of the chosen GPU API. As a purely practical matter, the GPU program is also embedded in the host program as a string literal. At runtime, the host program will pass the GPU program to the kernel compiler provided by the GPU driver, which will generate machine code for the actual GPU.
The OpenCL backend was the first to be implemented, starting in around 2015 and becoming operational in 2016. The CUDA backend was implemented by Jakob Stokholm Bertelsen in 2019, largely in imitation of the OpenCL backend, motivated by the somewhat lacking enthusiasm for OpenCL demonstrated by NVIDIA. For similar reasons, the HIP backend was implemented by me in 2023. While one could think the OpenCL backend would be more mature purely due to age, the backends make use of the same optimisation pipeline and, as we shall see, almost the same code generator, and so produce code of near identical quality.
The difference between the code generated by the three GPU backends is (almost) exclusively down to which GPU API is invoked at runtime, and the compiler defines a thin abstraction layer that is targeted by the code generator and implemented by the three GPU backends. There is no significant difference between the backends regarding how difficult this portability layer is to implement. CUDA requires 231 lines of code, HIP 233, and OpenCL 255 (excluding platform-specific startup and configuration logic).
The actual GPU code is pretty similar between the three backends (CUDA C, OpenCL C, and HIP C), and largely papered over by thin abstraction layers and a nest of #ifdefs. This is partially because Futhark does not make use of any language-level abstraction features and merely uses the human-readable syntax as a form of portable assembly code. One thing we do require is robust support various integer types, which is fortunately provided by all of CUDA, OpenCL, and HIP. (But not by GPU APIs mostly targeted at graphics, which I will briefly return to later.)
One reason for why we manage to paper over the differences so easily is of course that Futhark doesn’t really generate very fancy code. The generated code may use barriers, atomics, and different levels of the memory hierarchy, which are all present in equivalent forms in our targets. But what we don’t exploit is things like warp-level primitives, dynamic parallelism, or tensor cores, which are present in very different ways (if at all) in the different APIs. That does not mean we don’t want to look at exploiting these features eventually, but currently we find that there’s still lots of fruit to pick from the more portable-hanging branches of the GPGPU tree.
Runtime compilation
Futhark embeds the GPU program as a string in the CPU program, and compiles it during startup. While this adds significant startup overhead (ameliorated through caching), it allows important constants such as thread block sizes, tile sizes, and other tuning parameters to be set dynamically (from the user’s perspective) rather than statically, while still allowing such sizes to be visible as sizes to the kernel compiler. This enables important optimisations such as unrolling of loops over tiles. Essentially, this approach provides a primitive but very convenient form of Just-In-Time compilation. Most CUDA programmers are used to ahead-of-time compilation, but CUDA actually contains a very convenient library for runtime compilation, and fortunately HIP has an equivalent.
Compilation model
The Futhark compiler does a lot of optimisations of various forms - all of which is identical for all GPU backends. Ultimately, the compiler will perform flattening after which all GPU operations are expressed as a handful of primitive (but still higher-order) segmented operations: maps, scans, reduces, and generalised histograms.
The code generator knows how to translate each of these parallel primitives to GPU code. Maps are translated into single GPU kernels, with each iteration of the map handled by a single thread. Reductions are translated using a conventional approach where the arbitrary-sized input is split among a fixed number of threads, based on the capacity of the GPU. For segmented reductions, Futhark uses a multi-versioned technique that adapts to the size of the segments at runtime. Generalised histograms are implemented using a technique based on multi-histogramming and multi-passing, with the goal of minimising conflicts and maximising locality. All of these are compiled the same way, although the generated code may query certain hardware properties (such as cache sizes and thread capacity), which I will return to.
The odd one out is scans. Using the CUDA or HIP backends, scans are implemented using the decoupled lookback algorithm (of course implemented by students), which requires only a single pass over the input, and is often called a single-pass scan. Unfortunately, the single-pass scan requires memory model and progress guarantees that are present in CUDA and HIP, but seem to be missing in OpenCL. Instead, the OpenCL backend uses a less efficient two-pass scan that manifests an intermediate array of size proportional to the input array. This is the only case for which there is a significant difference in how the CUDA, HIP, and OpenCL backends generate code for parallel constructs.
Results
To evaluate the performance of Futhark’s GPU backends, I measured 48 benchmark programs from our benchmark suite, ported from Accelerate, Parboil, Rodinia, and PBBS. Some of these are variants of the same algorithm, e.g., there are five different implementations of breadth-first search. I used an NVIDIA A100 GPU and an AMD MI100 GPU. This is certainly an experiment that focuses on breadth rather than depth. I am not familiar with any benchmark suite that has so many equivalent programs written using different GPU APIs. Certainly, a human programmer would never do anything this tedious, although on the other hand a human programmer would probably take better advantage of the peculiarities of each API.
Most of the benchmarks contain multiple workloads of varying sizes. Each workload is executed at least ten times, and possibly more in order to establish statistical confidence in the measurements. For each workload, I measure the average observed wall clock runtime. For a given benchmark executed with two different backends on the same GPU, I then report the average speedup across all workloads, as well as the standard deviation of speedups.
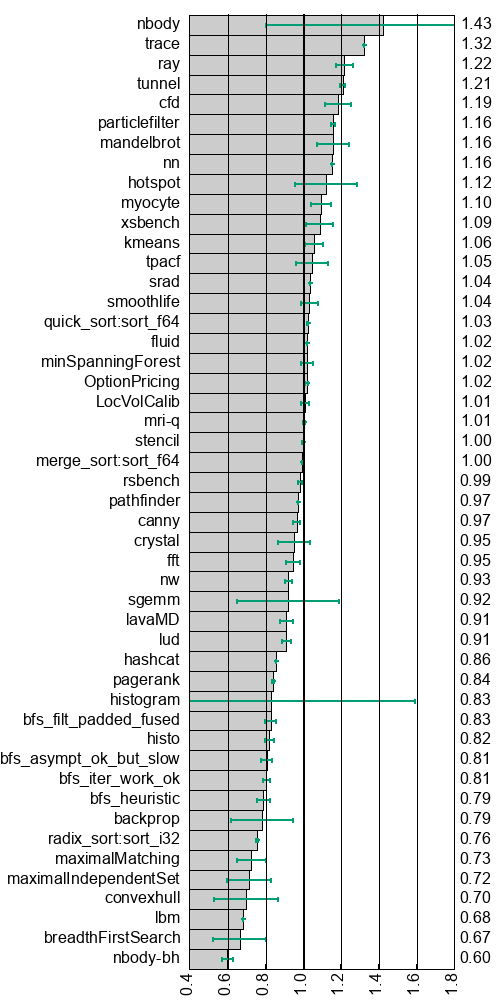
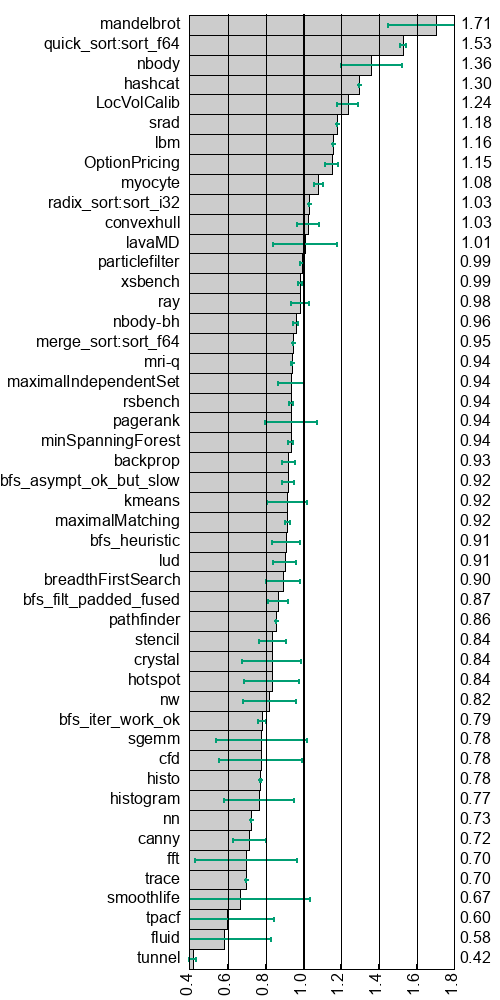
The speedup of using the OpenCL backend relative to the CUDA backend on A100 can be seen below, in the left column, and similarly for OpenCL relative to HIP on MI100 to the right. A number higher than 1 means that OpenCL is faster than CUDA or HIP, respectively. A wide error bar indicates that the performance difference between backends is different for different workloads. (I had some trouble figuring out a good way to visualise this rather large and messy dataset, but I think it ended up alright.)
| A100 (CUDA vs OpenCL) | MI100 (HIP vs OpenCL) |
|---|---|
|
|
More details on the methodology, and how to reproduce the results, can be found here.
Analysis
In an ideal world, we would observe no performance differences between backends. However, as mentioned above, Futhark does not use equivalent parallel algorithms in all cases. And even for those benchmarks where we do generate equivalent code no matter the backend, we still observe differences. The causes of these differences are many and require manual investigation to uncover, sometimes requiring inspection of generated machine code. (Rarely fun at the best of times, and certainly when you have a large benchmark suite.) Still, I managed to isolate most causes of performance differences.
Cause: Defaults for numerical operations
OpenCL is significantly faster on some benchmarks, such as
mandelbrot on MI100, where it outperforms HIP by 1.71x. The reason
for this is that OpenCL by default allows a less numerically precise
(but faster) implementation of single-precision division and square
roots. This is presumably for backwards compatibility with code
written for older GPUs, which did not support correct rounding. The
OpenCL build option -cl-fp32-correctly-rounded-divide-sqrt forces
correct rounding of these operations, which matches the default
behaviour of CUDA and HIP. These faster divisions and square roots
explain most of the performance differences for the benchmarks
nbody, trace, ray, tunnel, and mandelbrot on both MI100 and
A100. Similarly, passing -ffast-math to HIP on MI100 makes it match
OpenCL for srad, although I could not figure out precisely what
effect this has on code generation in this case.
An argument could be made that the Futhark compiler should automatically pass the necessary options to ensure consistent numerical behaviour across all backends (related issue).
Cause: Different scan implementations
As discussed above, Futhark’s OpenCL backend uses a less efficient two-pass scan algorithm, rather than a single-pass scan. For benchmarks that make heavy use of scans, the impact is significant. This affects benchmarks such as nbody-bh, all BFS variants, convexhull, maximalIndependentSet, maximalMatching, radix_sort, canny, and pagerank. Interestingly, the quick_sort benchmark contains a scan operator with particularly large operands (50 bytes each), which interacts poorly with the register caching done by the single-pass scan implementation. As a result, the OpenCL version of this benchmark is faster on the MI100.
This is probably the least surprising cause of performance differences (except for quick_sort, which I hadn’t thought about).
Cause: Smaller thread block sizes
For mysterious reasons, AMD’s implementation of OpenCL limits thread blocks to 256 threads. This may be a historical limitation, as older AMD GPUs did not support thread blocks larger than this. However, modern AMD GPUs support up to 1024 threads in a thread block (as does CUDA) and this is fully supported by HIP. This limit means that some code versions generated by incremental flattening are not runnable with OpenCL on MI100, as the size of nested parallelism (and thus the thread block size) exceeds 256, forcing the program to fall back on fully flattened code versions with worse locality. The fft, smoothlife, nw, lud, and sgemm benchmarks on MI100 suffer most from this. The wide error bars for fft and smoothlife are due to only the largest workloads being affected.
Cause: Imprecise cache information
OpenCL makes it more difficult to query some hardware properties. For
example, Futhark’s implementation of generalised histograms uses the
size of the GPU L2 cache to balance redundant work with reduction of
conflicts through a multi-pass technique. With CUDA and HIP we can
query this size precisely, but OpenCL does not reliably provide such a
facility. On AMD GPUs, the CL_DEVICE_GLOBAL_MEM_CACHE_SIZE property
returns the L1 cache size, and on NVIDIA GPUs it returns the L2
cache size. The Futhark runtime system makes a qualified guess that is
close to the correct value, but which is incorrect on AMD GPUs. This
affects some histogram-heavy benchmarks, such as (unsurprisingly)
histo and histogram, as well as tpacf.
Cause: Imprecise thread information
OpenCL makes it difficult to query how many threads are needed to fully occupy the GPU. On OpenCL, Futhark makes a heuristic guess (the number of compute units multiplied by 1024), while on HIP and CUDA, Futhark directly queries the maximum thread capacity. This information, which can be manually configured by the user as well, is used to decide how many thread blocks to launch for scans, reductions, and histograms. In most cases, small differences in thread count have no performance impact, but hashcat and myocyte on MI100 are very sensitive to the thread count, and run faster with the OpenCL-computed number.
This also occurs with some of the histogram datasets on A100 (which explains the enormous variance), where the number of threads is used to determine the number of passes needed over the input to avoid excessive bin conflicts. The OpenCL backend launches fewer threads and performs a single pass over the input, rather than two. Some of the workloads have innately very few conflicts (which the compiler cannot possibly know, as it depends in run-time data), which makes this run well, although other workloads run much slower.
The performance difference can be removed by configuring HIP to use the same number of threads as OpenCL. Ideally, the thread count should be decided on a case-by-case basis through auto-tuning, as the optimal number is difficult to determine analytically.
Cause: API overhead
For some applications, the performance difference is not attributable to measurable GPU operations. For example, trace on the MI100 is faster in wall-clock terms with HIP than with OpenCL, although profiling reveals that the runtimes of actual GPU operations are very similar. This benchmark runs for a very brief period (around 250 microseconds with OpenCL), which makes it sensitive to minor overheads in the CPU-side code. I have not attempted to pinpoint the source of these inefficiencies, I have generally observed that they are higher for OpenCL than for CUDA and HIP (but also that it is quite system-dependent, which doesn’t show up in this experiment).
Benchmarks that have a longer total runtime, but small individual GPU operations, are also sensitive to this effect, especially when the GPU operations are interspersed with CPU-side control flow that require transfer of GPU data. The most affected benchmarks on MI100 include nn and cfd. On A100, the large variance on nbody is due to a small workload that runs in 124 microseconds with OpenCL, but 69 microseconds with CUDA, where the difference due to API overhead, and similar case occurs for sgemm.
Cause: Bounds checking
Futhark supports bounds checking of code running on GPU, despite lacking hardware support, through a program transformation that is careful never to introduce invalid control flow or unsafe memory operations. While the overhead of bounds checking is generally quite small (around 2-3%), I suspect that its unusual control flow can sometimes inhibit kernel compiler optimisations, with inconsistent impact on CUDA, HIP, and OpenCL. The lbm benchmark on both MI100 and A100 is an example of this, as the performance difference between backends almost disappears when compiled without bounds checking.
Cause: It is a mystery
Some benchmarks show inexplicable performance differences, where I could not figure out the cause. For example, LocVolCalib on MI100 is substantially faster with OpenCL than HIP. The difference is due to a rather complicated kernel that performs several block-wide scans and stores all intermediate results in shared memory. Since this kernel is compute-bound, its performance is sensitive to the details of register allocation and instruction selection, which may differ between the OpenCL and HIP kernel compilers. GPUs are very sensitive to register usage, as high register pressure lowers the number of threads that can run concurrently, and the Futhark compiler leaves all decisions regarding register allocation to the kernel compiler. Similar inexplicable performance discrepancies for compute-bound kernels occur on the MI100 for tunnel and OptionPricing.
Reflections
Based on the results above, we might reasonably ask whether targeting OpenCL is worthwhile. Almost all cases where OpenCL outperforms CUDA or HIP are due to unfair comparisons, such as differences in default floating-point behaviour, or scheduling decisions based on inaccurate hardware information that happens to perform well by coincidence on some workloads. On the other hand, when OpenCL is slow, it is because of more fundamental issues, such as missing functionality or API overhead.
One argument in favour of OpenCL is its portability. An OpenCL program can be executed on any OpenCL implementation, which includes not just GPUs, but also multicore CPUs and more exotic hardware such as FPGAs. However, OpenCL does not guarantee performance portability, and it is well known that OpenCL programs may need significant modification in order to perform well on different platforms. Indeed, the Futhark compiler itself uses a completely different compiler pipeline and code generator in its multicore CPU backend.
A stronger argument in favour of OpenCL is that it is one of the main APIs for targeting some hardware, such as Intel Xe GPUs. I’d like to investigate how OpenCL performs compared to the other APIs available for that platform.
Finally, a reasonable question is whether the differences we observe are simply due to Futhark generating poor code. While this possibility is hard to exclude generally, Futhark tends to perform competitively with hand-written programs, in particular for the benchmarks considered in this post, and so it is probably reasonable to assume that the generated code is not pathologically bad to such an extent that it can explain the performance differences.
The Fourth Backend
There is actually a backend that is missing here - namely the embryonic WebGPU backend developed by Sebastian Paarmann. The reason is pretty simple: it’s not done yet, and cannot run most of our benchmarks. Although it is structured largely along the same lines as the existing backends (including using the same GPU abstraction layer), WebGPU has turned out to be a far more hostile target:
The WebGPU host API is entirely asynchronous, while Futhark assumes a synchronous model. We have worked around that by using Emscriptens support for “asyncifying” code, combined with some busy-waiting that explicltly relinquishes control to the browser event loop.
The WebGPU Shader Language is more limited than the kernel languages in OpenCL, CUDA, and HIP. In particular it imposes constraints on primitive types, pointers, and atomic operations that are in conflict with what Futhark (sometimes) needs.
More details can be found in Sebastian’s MSc thesis, and we do intend to finish the backend eventually. (Hopefully, WebGPU will also become more suited for GPGPU, as well as more robust - it is incredible how spotty support for it is.)
However, as a very preliminary performance indication, here are the runtimes for rendering an ugly image of the Mandelbrot set using an unnecessary amount of iterations, measured on the AMD RX 7900 in my home desktop computer:
HIP: 13.5ms
OpenCL: 14.4ms
WebGPU: 18.4ms
WebGPU seems to have a fixed additional overhead of about 3-4ms in our measurements - it is unclear whether our measurement technique is wrong, or whether we are making a mistake in our generated code. But for purely compute-bound workloads, WebGPU seems to keep up alright with the other backends (at least when it works at all).
You can also see the WebGPU backend in action here, at least if your browser supports it.
Future
This experiment was motivated by my own curiosity, and I’m not quite sure where to go from here, or precisely which conclusions to draw. Performance portability seems inherently desirable in a high level language, but it’s also an enormous time sink, and some of the problems don’t look like things that can be reasonably solved by Futhark (except through auto-tuning).
I’d like to get my hands on a high-end Intel GPU and investigate how Futhark performs there. I’d also like to improve futhark autotune such that it can determine optimal values for some of the parameters that are currently decided by the runtime system based on crude analytical models and assumptions.
One common suspicion I can definitely reject is that NVIDIA does not seem to arbitrarily sabotage OpenCL on their hardware. While NVIDIA clearly doesn’t maintain OpenCL to nearly the same level as CUDA (frankly, neither does AMD these days), this manifests itself as OpenCL not growing any new features, rather than the code generation being poor.