How Futhark implements bounds checking on the GPU
Futhark is supposed to be a safe programming language. This implies
that risky operations, such as a[i] which indexes an array at some
arbitrary index, should be protected with a dynamic check. While C
programmers are famous for never making mistakes, and therefore C does
not perform such checking, the vast majority of programming
languages do check array indexes, usually by generating code like
this:
if (i < 0 || i > n) {
// throw exception
// OR print error message
// OR terminate program
// OR do anything else
}This immediately changes the control flow of the program based on the bounds check. Usually the implementation challenge is not how to perform such checks in the first place, but how to eliminate them in cases where the compiler can statically determine that the check can never fail. However, for Futhark we would like to generate code for GPUs, and GPUs are great at turning solved problems unsolved.
In this post I will describe why it took Futhark years to get support for bounds-checking on the GPU, how we recently solved the problem, and what the performance is like. This post is a rewritten extract of a recently presented paper, which you can read if you are particularly interested in the details of bounds checking.
Asynchronous execution
The basic problem is that the GPU functions as a co-processor that receives data and code from the CPU, but which is then processed at the GPUs own pace. Explicit synchronisation and copying (both slow) is necessary to exchange information between the CPU and GPU.
GPU code is organised as kernels (no relation to operating systems, more like functions), and when we launch code on the GPU, we tell it to run a specific kernel with a specific number of threads, with some specific arguments. It’s a lot like performing an asynchronous remote procedure call. And similarly to a remote procedure, a kernel that contains an index that is out of bounds has no way of directly affecting the control flow of the CPU. In practice, our only option is to simply write a value to a distinguished memory location indicating that things have gone wrong, and then terminate the running GPU thread:
if (i < 0 || i >= n) {
*global_failure = 1;
return; // Terminate GPU thread
}On the CPU, whenever we launch a GPU kernel, we then block until the
kernel is done running, copy back the global_failure value, and
check whether a bounds error occurred:

Surely reading a single number after every kernel (which usually processes tens of thousands of array elements) must be fast? Let’s check the overhead on the Futhark benchmark suite, measured on an RTX 2080 Ti GPU:
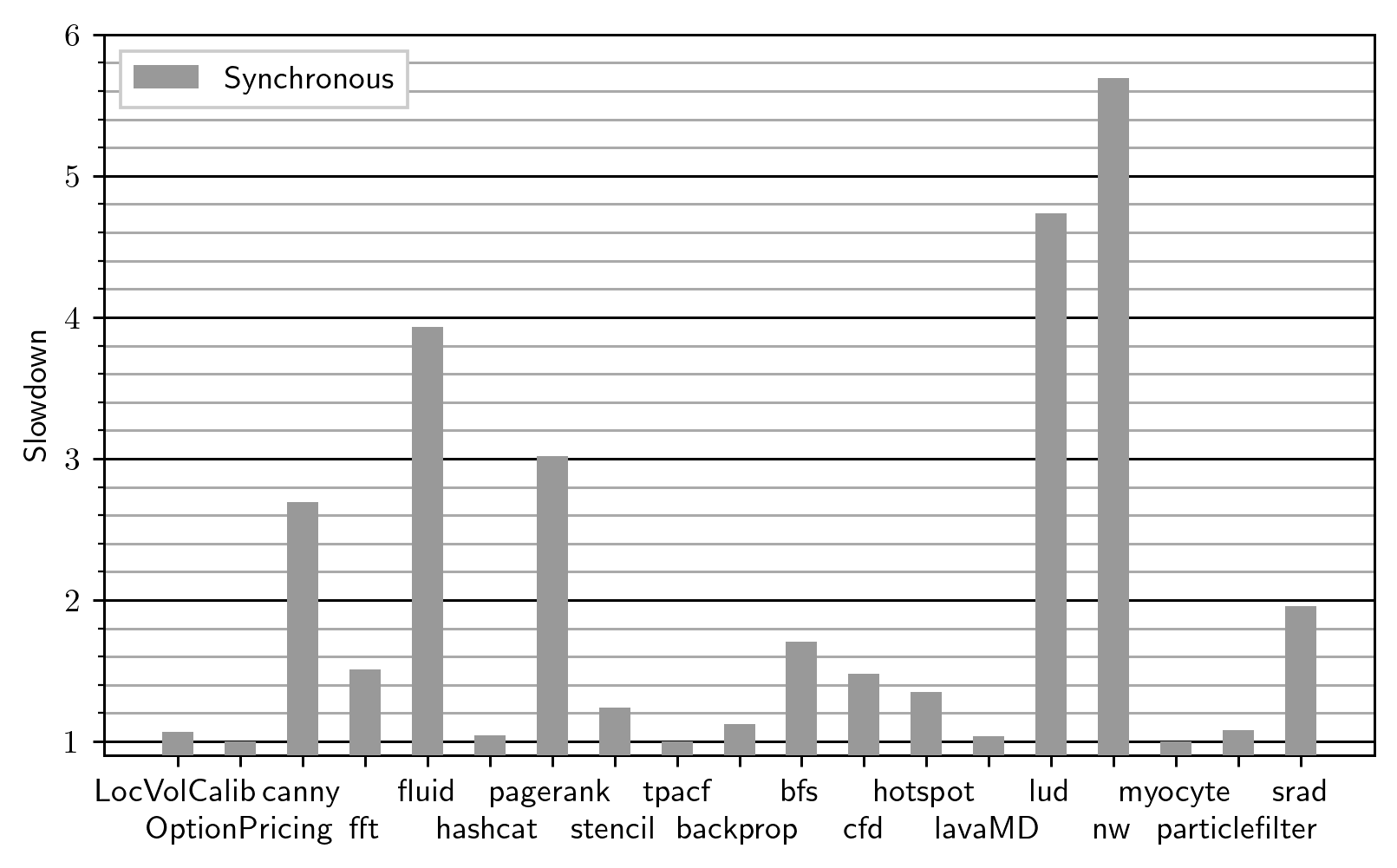
The vertical axis shows the slowdown of synchronous bounds checking compared to not doing any bounds checking. The overhead is pretty bad: A geomean of 1.66x , and more than 6x on the worst affected benchmarks. I’m only measuring those benchmarks that require bounds checking at all, so the mean overhead across all benchmarks would be lower. Still, this is too slow to be practical.
GPUs perform well when given a large queue of work to process at their own pace, not when they constantly stop to transfer 32 bits back to the CPU for inspection, and have to wait for a go-ahead before proceeding. To speed this up, we need to cut the amount of synchronisation.
Let’s take a step back and consider why we do bounds checking in the
first place: we want to avoid corrupting memory by writing to invalid
addresses, and we want to avoid making bad control flow decisions
based on reading garbage. This implies that we have to do bounds
checking immediately whenever we access an array. But since the
GPU’s control flow is completely decoupled from what is happening on
the CPU, the CPU doesn’t actually need to know immediately that
something has gone wrong - it only needs to be informed when it
eventually copies data from the GPU, so that it knows not to trust it.
The actual check still needs to be done immediately on the GPU, but
copying back global_failure to the CPU can wait until the CPU
would in any case need to synchronise with the GPU:

This amortises the copying overhead over potentially many kernel
launches. But we’re still not quite done, as kernel i+1 may contain
unchecked operations that are safe if and only if the preceding kernel
i completed successfully. To address this, we add a prelude to
every GPU kernel body where each thread checks whether
global_failure is set:
// Prelude added to every GPU kernel
if (*global_failure) {
return;
}If so, that must mean one of the preceding kernels has encountered a
failure, and so the all threads of the current kernel terminate
immediately. Checking global_failure on the GPU is much faster
than checking it on the CPU, because it does not involve any
synchronisation or copying. The overhead is a single easily cached
global memory read for every thread, which is in most cases
negligible. Asynchronous checking performs like this:
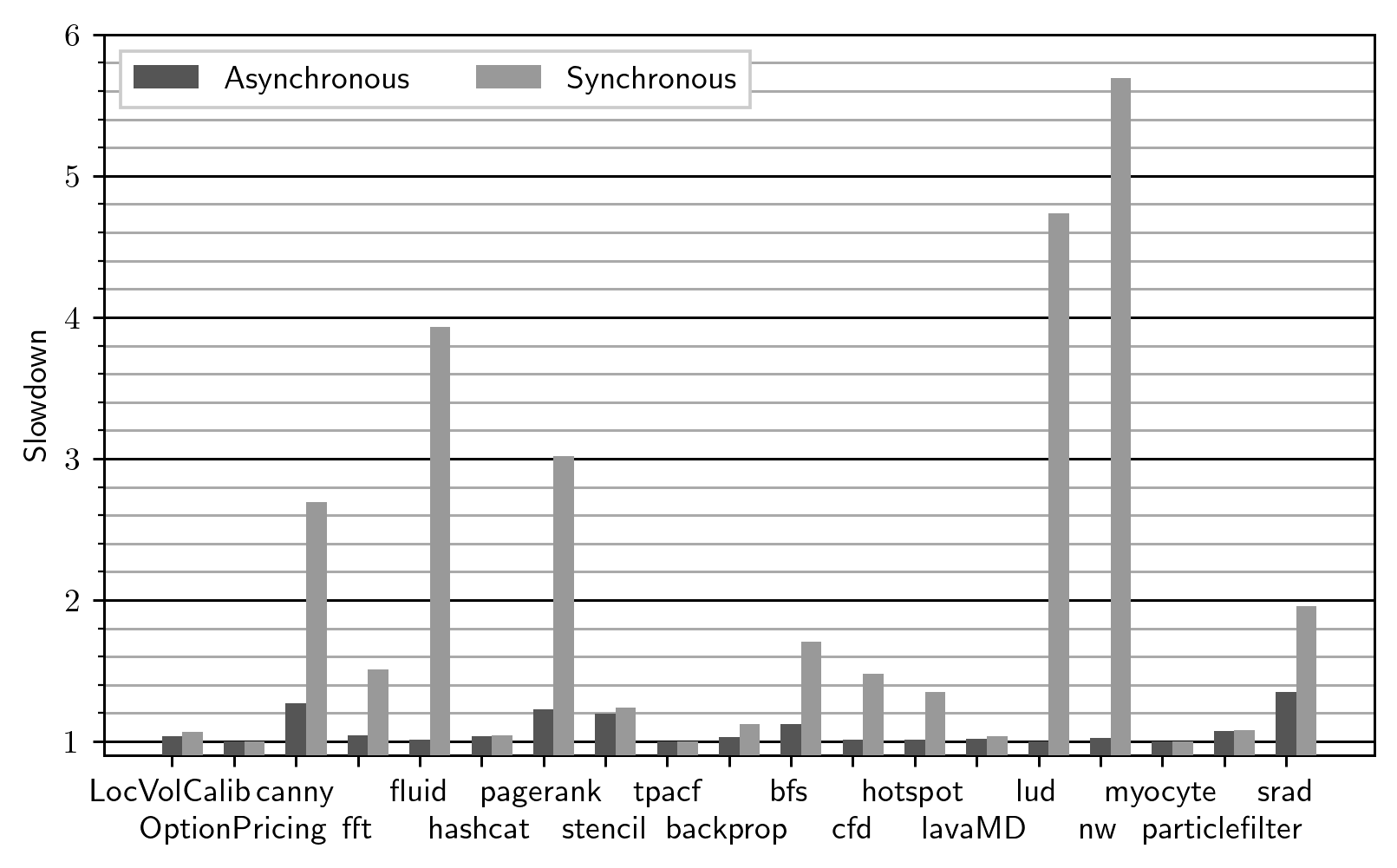
Much better! The mean overhead is down to 1.07x (compared to 1.66x before), and the maximum overhead is 1.4x (6x before). The slowest program is now the srad benchmark, which is structured roughly as follows:
loop image for i < 100 do
let x = reduce ... image
let image' = map (f x) image
in image'The reduce runs on the GPU but produces a scalar, which in
Futhark’s compilation model is copied back to the CPU where a tiny
amount of sequential computation takes place, after which it is used
to update the image array in various ways. The fact that we copy
a value (even just a single number!) back to the CPU forces us to do a
full synchronisation and also check global_failure. This is
because the compiler is conservative - it does not understand that
x is not going to be used for any CPU-side control flow, but is
instead going to be sent right back to the GPU. Since each instance
of reduce and map run for extremely short periods (little more
than a dozen microseconds each), the communication cost becomes
significant. This was already a problem, but bounds checking makes it
worse.
The solution to this is not directly related to bounds checking at
all, but is about refining our compilation model such that individual
scalars are more aggressively kept on the GPU, if we can determine
that their value is not truly needed on the CPU. As a side effect,
this will allow us to delay checking global_failure until the
entire outermost sequential loop has run, which will make the overhead
of bounds checking essentially zero. But this is future work.
Cross-thread communication
So far, we have assumed that a GPU thread, upon encountering an error, can safely terminate itself, or even the entire kernel. Unfortunately, reality is not so forgiving. A GPU thread can terminate itself, sure, but this can induce deadlocks if the kernel contains barriers, because other threads may be waiting for the now-terminated thread. Life would be easier if the prevailing GPU APIs (CUDA and OpenCL) provided a way for a single thread to unilaterally abort execution of the entire kernel, but they don’t. The solution to this is a little hairy, and involves the failing thread jumping ahead to the next barrier instead of simply terminating, then after each barrier checking whether any threads have failed. See the paper for the full details. It’s a solution that relies heavily on all communication being under the control of the compiler, so it’s not something you could do for a low-level GPU language.
Optimisations
All effective and elegant implementation techniques must inevitably be followed by a collection of ad-hoc micro-optimisations of dubious impact, and bounds checking in Futhark is no different. Some of the special cases we handle are as follows:
- Certain particularly simple kernels are able to execute safely even when previous kernels have failed, typically because they merely copy or replicate memory. Matrix transposition is an example of such a kernel. For these kernels we can eliminate all failure checking entirely, because bounds failures cannot result in memory becoming inaccessible, it can only result in the values stored being wrong, and these simple kernels are not sensitive to the values they are copying.
- Some kernels may contain no bounds checks. They still need to check whether any previous kernels have failed, but do not need to be careful with respect to barriers and such.
- At run-time, whenever we enqueue a kernel, we have dynamic
knowledge of whether any kernels with bounds checks have been
enqueued since the last time
global_failurewas checked. That is, we know dynamically whetherglobal_failureis certainly unset. If so, we can pass that information along to the kernel as a kernel argument, which means the kernel does not have to check the value ofglobal_failurein its prelude.
The impact of these optimisations (and others covered in the paper) is quite minor, as shown in the following graph.
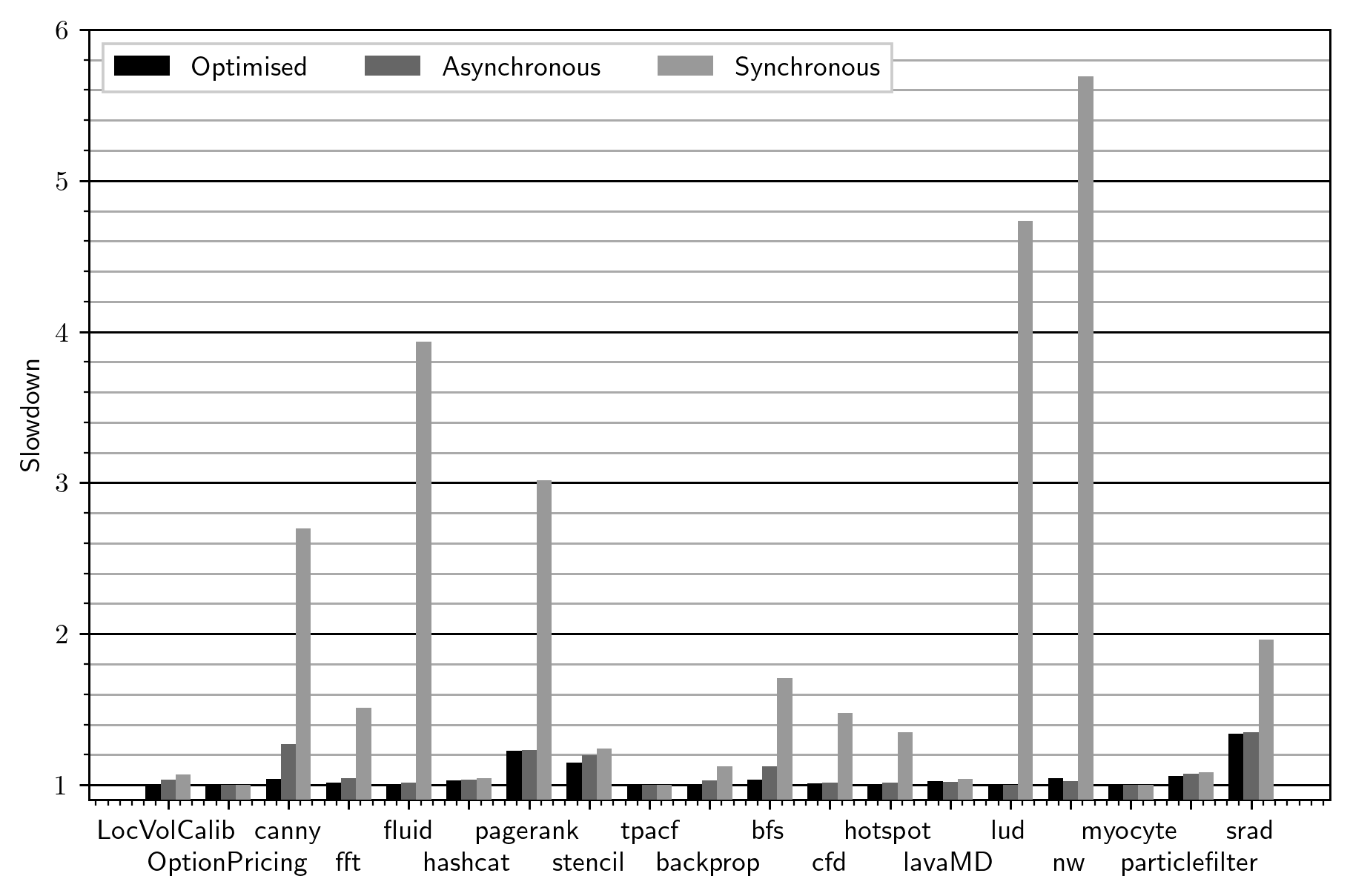
Most of the optimisations were motivated by micro-benchmarks, where the impact is more significant. On these benchmarks, they reduce the mean overhead to 1.04x (from 1.07x), and have no impact on the maximum overhead. Useful, but not crucial the way asynchronous checking is.
Error messages
As discussed above, global_failure contains only a single bit of
information: did the program fail or not? But the modern programmer
is accustomed to luxuries such as being told where it failed, so
clearly this will not do. The solution is simple. At compile time,
we associate each bounds check with a unique number, a failure code,
with a global_failure value of -1 meaning no error so far.
When a bounds check fails, the thread writes the failure code
corresponding to the bounds check. At compile-time we also construct
a table that maps each failure code to a printf()-style format
string such as the following:
"index %d out of bounds for array of size %d"For simplicity, %d is the only format specifier that can occur,
but each distinct format string can contain a different number of
format specifiers. We then pre-allocate an int array
global_failure_args in GPU memory that is big enough to hold all
parameters for the largest format string. When a thread changes
global_failure, it also writes to global_failure_args the
integers corresponding to the format string arguments. We have to be
careful that if multiple threads fail around the same time, only one
also updates global_failure_args. This can be done with atomics.
It looks a bit like this in GPU code:
if (i < 0 || i >= n) {
// Atomic compare-and-exchange, set only if current value is -1
if (atomic_cmpxchg(global_failure, -1, 0) < 0) {
// We managed to set global_failure
global_failure_args[0] = i;
global_failure_args[1] = n;
}
return; // Stop thread
}When the CPU detects the failure after reading global_failure, it
uses the failure code to look up the corresponding format string and
instantiates it with arguments from global_failure_args. Note
that the CPU only accesses global_failure_args when a failure has
occurred, so performance of the non-failing case is not affected.
Evaluation
Bounds checking on GPU was added in Futhark 0.15.1 and quickly proved
its worth. In retrospect we should have implemented it a long time
ago, given the simplicity of the implementation and that it uses
absolutely no recent or fancy GPU features, nor depends on
sophisticated compiler infrastructure. For years I was blinded by the
fact that GPU APIs do not provide direct support for handling
erroneous execution in non-fatal ways. While bounds checking has been
the central example for this post, this technique can actually be used
to handle any safety check, and the compiler also uses it to check
for things such as integer division by zero and to handle
programmer-written assert expressions. Bounds checking by default
is clearly the right choice, and it is easy to disable either locally
or globally for those programs that need the last bit of performance,
or whenever a perfect superperson programmer feels the need to do a
bit of functional array programming.
There are some important properties of Futhark that made this efficient implementation possible. Most crucially, failure is not observable within the language itself. There is no way, in a Futhark program, to handle that some array index has gone wrong. That information is only propagated to the caller of the Futhark entry point (likely called through the C API). This is a key part of why the asynchronous implementation is valid, as there is no “error handling” scope we have to respect.
In fact, while Futhark is a deterministic language, bounds failures are explicitly not part of its defined semantics. This means that if two threads fail at around the same time, it is OK for the implementation to be nondeterministic about which of the two failures will end up being reported. This saves us a lot of expensive synchronisation.
Finally, I should note that as Futhark is an array language, the vast majority of array accesses are compiler-generated, and guaranteed correct-by-construction. Bounds checking is only needed when doing manual array indexing, which is mostly used in irregular programs or encodings, for example when encoding graphs as arrays. In fact, only about half of our benchmark suite contains explicit indexing in its generated GPU code.