Futhark server mode and Literate Futhark
Futhark is a purely functional language designed for numerical code. It does not have the ability to do IO. This makes it impossible to write entire applications in Futhark. You can compile a Futhark program to an executable that will read input from stdin and produce the result on stdout. This is fine for small-scale testing, but not useful for entire applications. A crucial limitation is that function parameters and arguments must be of types that have a well-defined external encoding. In practice, this means built-in primitive types and arrays of these, with no support for records and sum types.
Alternatively, you can compile Futhark to library code, which can be invoked from any language with a C FFI. This works well for real applications, and maps complex types to opaque structs, but is tedious when you want to play around with visualisations or simple data analysis. In this post I will talk about recent work I did to bridge the gap, with an eye towards making it easier to write tools that interact with compiled Futhark programs, but without generating any custom C code. I’ll also show how I used this new technique to write a new tool for notebook-ish “literate” Futhark programming.
Futhark server mode
When you compile Futhark to a C library, the resulting code behaves like you’d expect: interim data is kept in some internal format (and possibly on the GPU), the API exposes handles to this data, and these can can be passed between entry points. For those types where it makes sense (mostly arrays of primitives), there are functions for converting to and from ordinary C values. The only downside is that if you have a program with two entry points:
entry foo (xs: []f32) = map (**2) xs
entry bar (xs: []f32) = map (+2) xsThen the only way to compose them without modifying the original
program is to write C code that first calls a generated
futhark_entry_foo() function and then passes the result on to
futhark_entry_bar().
Why is this a problem? Well, suppose you wanted to do
property-based
testing
and test the property “any nonempty composition of foo and bar
functions will run correctly and produce an array of positive
numbers”. Normally we would build testing libraries in the
language itself
(e.g. QuickCheck
for Haskell), but Futhark is intentionally not sufficiently
expressive to do this - in particular, errors cannot be captured
and handled. However, it is really awkward to generate and compile
custom C programs that link against the compiled Futhark library
whenever the tools want to test a case.
To enable these kinds of tools, I added a third way of compiling Futhark programs: server mode. This mode produces an executable, but instead of executing a single entry point with input read from stdin, the program instead reads commands passed on stdin, which can load data from files, call entry points, save values to files, etc. It’s quite REPL-like, except that the protocol is not intended for direct human use, but is meant to be used by tools. Server mode does not allow arbitrary Futhark expressions to be sent (run-time compilation is not conductive to desert survival), but you can call any entry point defined in the program. In essence, it’s a thin text-based wrapper around the C API, and has the same limitations (notably, entry points must be monomorphic and first-order).
A session might look like this (with an artificially added input prompt for ease of reading):
> restore /tmp/whatever.in input []f32
%%% OKThis creates a server variable input that contains an array of
type []f32 read from the file /tmp/whatever.in. The server
responds with %%% OK when it is ready for the next command. To
keep the protocol entirely text-based, all binary IO is done
out-of-band by writing to (typically) temporary files.
We can then call an entry point and put the result in a new server variable:
> call foo out0 input
%%% OKThis runs foo on input and creates a new variable out0 with
the result. We can then pass out0 on to another entry point:
> call bar out1 out0
%%% OKAnd when we are done with a variable:
> free out0
%%% OKA hypothetical property testing tool might do this any number of times based on its own search strategy, and then write the final (or intermediate) results to a file:
> store /tmp/result.out out1After which it can read the value encoded in a simple binary data format from the given file, and verify that it is as expected. Internally, these operations might have involved talking to the GPU, or doing multicore execution - but the protocol is the same.
One significant upside of server mode is that we can run an arbitrary number of entry points in the same process. Previously, our testing and benchmarking tools generated executables, and thus had to initialise the Futhark context for every entry point and dataset. Context initialisation may involve GPU setup as well as dynamic compilation of GPU kernels, which can take several seconds - typically dwarfing the actual cost of running the code. After changing the testing and benchmarking tools to use server mode and keep the same program instance running for all entry points and datasets, the time to run our reduce micro-benchmark dropped from 10 minutes to 30 seconds. This is an extreme case, as this program has 28 entry points with a handful of datasets each, where actually running each dataset typically takes just a few milliseconds. But all benchmarks with more than one dataset benefited, even if not to such an extreme degree. Note that this has no effect on the benchmark results - all we optimised here is the tooling.
Literate Futhark
I mentioned property testing as a motivating example above, but that’s not actually what I ended up using server mode for. I have long desired an easy way to write example programs that automatically embedded the result of evaluating the code. It wouldn’t be hard to use the Futhark interpreter to build such a tool, but the interpreter is super slow, and sometimes I want to show off programs that have a lot of computation in them. Server mode is exactly what I need.
For example, suppose I have this function:
let fact (n: i32) = i32.product (1...n)Cool, right?
Now dig this:
> (fact 10i32, fact 15i32)(3628800i32, 2004310016i32)The blog post you are reading is actually a literate Futhark program. If you check the source (and scroll down a bit), you’ll see that it’s a perfectly ordinary Futhark program, with all the prose contained in comments. The expression above is written as a specially formatted comment, called an evaluation directive:
-- > (fact 10i32, fact 15i32)When we run futhark literate 2021-01-18-futharkscript.fut, the
tool produces a file 2021-01-18-futharkscript.md where code and
prose has been marked up appropriately, and all evaluation
directives have been augmented with the result of their execution.
A Markdown processor (Pandoc in my case)
then turns it into HTML, or whatever else you want. Internally,
futhark literate compiles the program as given in server mode,
then uses the compiled program to process any evaluation
directives. No custom code generation or run-time compilation
takes place.
So how does this work in the absence of run-time compilation?
Well, by cheating of course. While the Futhark definitions (like
fact) are completely ordinary Futhark code and are processed by
the Futhark compiler as normal, the directives only support a
tiny subset of Futhark syntax called FutharkScript. Considering
FutharkScript a language is borderline: as of this writing, all it
supports is function calls, tuple and record literals, and numeric
constants with mandatory type suffixes. The idea is that you put
all the real logic inside entry points, and keep the FutharkScript
expressions very simple. When futhark literate executes
FutharkScript, it does this by loading data with restore,
handling function calls with call, and finally using store to
obtain the results. It works surprisingly well.
Fancier directives
Some functions results are better interpreted as image data than as raw numbers.
entry mkimg (h: i64) (w: i64) =
let pix (r, g, b) = ((u32.f64 (r * 255) & 0xFF) << 16) |
((u32.f64 (g * 255) & 0xFF) << 8) |
(u32.f64 (b * 255) & 0xFF)
in tabulate_2d h w (\i j -> pix (f64.cos (f64.i64 i/10),
f64.cos (f64.i64 j/10),
f64.i64 i / f64.i64 h))So we use the :img directive:
> :img mkimg 100i64 300i64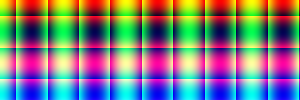
This requires the expression to be of a type that futhark literate knows how to interpret as image data, and which is then
turned into a Netpbm
6P image file (because
it’s easy), after which it shells out to
ImageMagick to convert it to a
PNG file.
Now suppose we need to do advanced data analysis.
let linspace (n: i64) (start: f64) (end: f64) : [n]f64 =
tabulate n (\i -> start + f64.i64 i * ((end-start)/f64.i64 n))
let xys f n start end =
unzip (map (\x -> (x, f x)) (linspace n start end))
entry plot_sqrt = xys f64.sqrt
entry plot_sin = xys f64.sin
entry plot_cos = xys f64.cos
entry plot_inv = xys (1/)The following directives shell out to gnuplot. Note how the labels are taken from the record field names.
> :plot2d {sqrt=plot_sqrt 1000i64 0.0f64 20.0f64,
sin=plot_sin 1000i64 0.0f64 20.0f64,
cos=plot_cos 1000i64 0.0f64 20.0f64,
inv=plot_inv 1000i64 1.0f64 20.0f64}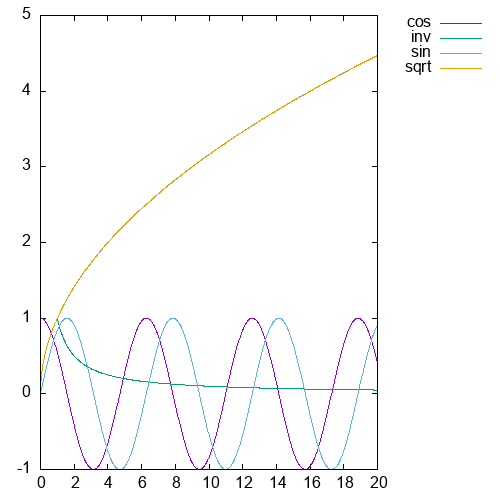
I like the retro appeal of gnuplot’s default settings, but maybe you’d rather write the commands yourself:
> :gnuplot {sin_10=plot_sin 10i64 0.0f64 20.0f64,
sin_1000=plot_sin 1000i64 0.0f64 20.0f64};
set key outside
set term png size 1000, 200
set style line 1 \
linecolor rgb '#0060ad' \
linetype 1 linewidth 1 \
pointtype 7 pointsize 1.5
plot sin_10 title '10 points' with linespoints linestyle 1, \
sin_1000 title '1000 points' with lines lw 1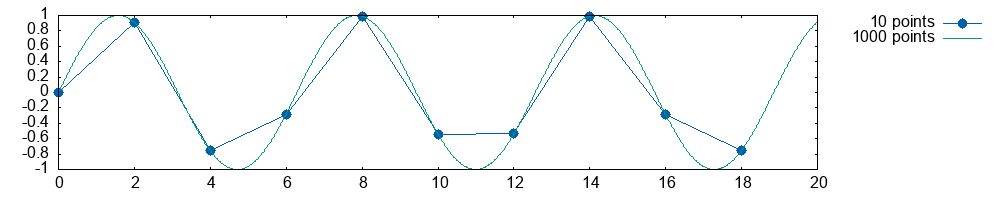
We can also do moving pictures!
let frames n h w =
let pix l i j : u32 =
let x = f32.i64 (-w/2+j)
let y = f32.i64 (-h/2+i)
let angle = f32.i64 l * (2*f32.pi / f32.i64 n)
let s = f32.sin angle
let c = f32.cos angle
let x' = x * c - y * s
let y' = x * s + y * c
in if f32.sgn x' == f32.sgn y'
then u32.f32 ((f32.sqrt (x'*x'+y'*y') /
f32.sqrt (f32.i64 (h/2*h/2+w/2*w/2)))
* 255)
else 0
in tabulate_3d n h w pixAnd then it’s just:
> :video frames 60i64 200i64 200i64;
fps: 60
loop: true
autoplay: trueThis shells out to ffmpeg to produce a .webm file. The
parameters following the semicolon are used to set attributes on
the eventual HTML <video> tag. The main downside of :video is
that we have to keep all the frames uncompressed in memory
simultaneously. This is fine for small videos, but we’ll probably
have to come up with a more incremental variant.
Conclusions
I’m pretty satisfied with futhark literate. I already changed
all our examples to be written in this style,
which has really jazzed up some of
them. In particular, I like that
the source is still normal Futhark source code, and you can load it
into futhark repl for debugging like you would any other Futhark
program.
It’s still a pretty crude tool however, and we’ll add new
directives as time goes on - benchmarking (with multiple different
backends) is certainly going to be added. I would also like to
extend FutharkScript with some handy impure functions for loading
data from image files and such. Futhark as a language is in the
awkward position that by its very design, it is (intentionally)
difficult to do quick and dirty things in it, but being quick and
dirty is still very useful for showing off the language! I hope
tools such as futhark literate can make it easy to explain and
visualise Futhark code, without complicating the language itself.
It would be nice if FutharkScript did not require type suffixes on number literals. Perhaps a small amount of type inference would be in order, or maybe just implicit conversions… it is a -Script language, after all.
Another issue is that all directives are recomputed whenever
futhark literate runs. This can be annoying when you have
(relatively) long-running directives such as the video above, which
remain unchanged while you work elsewhere in the document.
Temporarily commenting them out works, but it would be nicer if
futhark literate could simply re-use the result of a previous
computation.